QRT&&QRF
- Published time
這篇文章來介紹一下 Quantile Regression 這個 model,他分成第一個部分是 Quantile Regression 跟 Regression Tree,這篇文章會針對這兩者都做完整的介紹.
Quantile Regression#
舉個例子
在等待外送的時候 會看到預估時間在一個範圍內
這裡用的就會是 Quantile Regression,他預測了一個可能 75 分位數和 25 分位數
所以 50% 的機率你會在這個時間內拿到你的餐點
就像我們拿固定 input 範圍下 y 的分佈做盒狀圖 這裡使用 7~8 公里的範圍內

可以看到百分之 75 會低於 26 百分之 25 會低於 18
損失函數的計算
- OLS

這樣子得到的是在給定 data 下的條件平均數
- Quantile

這樣子得到的是給定 data 下的條件分位數
如果想成分佈的話,每個 data 產生的 y 都會是一個分布,我們今天只是去取這個分佈的百分位數會是多少,如果我們今天是用 OLS 去做的話,我們還需要先假設它的分布,通常都是假設常態分布,但誤差項不一定是穩定的分布,我們無從得知,但 quantile regression,每個分位數會有自己的參數,他們的反應也會不一樣.
其實最重要的就是這個損失函數,但這邊沒有要證明這個數學式,但今天無論是什麼模型套用到這個損失函數,他就會得到分量回歸的結果,但他一次只能預測一個分位數,所以想要幾個分位數,就要訓練幾次.
他的強項是在於 Y 可能會因為在不同的級距,有不同的分布的,一樣舉外送的例子,可能在較近的距離,他受到紅綠燈的影響就會比較小,但在較長的距離,可能就會受到紅綠燈的影響較大,再舉個例子,以財報預測報酬而言,可能在報酬率更高時,他會受到其中的特定關鍵字更敏感,報酬率較小的時候,他受到這個特定關鍵字的影響比較小.
如果以 OLS 跟 Qunatile Regression 預測 50 百分位數來比的話,前者受到極端值的影響較大,後者不會受到極端值的影響,因爲他針對誤差不需要任何假設.
Regression Tree#
決策樹的目的是在給定新的 data input,他能根據特徵值的切分,一路找到對應的輸出值.
所以在訓練時,他做的就是將特徵空間切分為很多個區塊
決策樹模型的圖示畫如下 :

每次分割時會尋找一個特徵跟其最佳切分點,將資料分為兩邊,一直分割直到設定的 depth,底下說明一下它的演算法流程
-
選擇最優解切分變量 白話 : 找所有 Feature + threshold
其中 c 是各自群組的平均值
-
根據所選切分變量 輸出值
這個輸出值指的就是當新的 input 在這個節點停下時,預測值為何
-
重複 1,2 直到滿足條件為止
-
最後將空間劃分 生成決策樹


上面這個是針對一般 regression ,他是用節點的平均值當作預測值,所以可以想像分完之後的結果就是所有資料被分類,每一個分類都有預測值,預測值和分類裡所有值差距最小的就是答案
Quantile Regression Tree#
如果結合以上兩者,其實就只是把 Regression Tree 裡的 loss function 改成

其中

所以可以想像最後的分類會是每一個分類的預測值變成是某個百分位數,在每個分類裡的每個值跟他預測值差最小,可能不是那麼直覺哈哈.
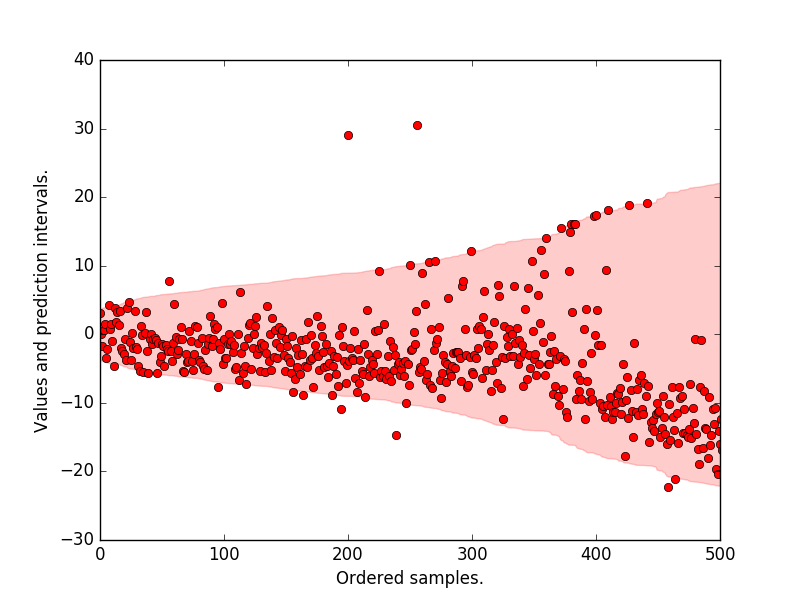
Quantile Regression Forest#
QRF 與隨機森林 (Random Forest) 的訓練方式相同: 它會生成許多決策樹,每棵樹都使用隨機抽樣的資料與特徵來訓練。 但關鍵的不同在於:Random Forest 在每個葉節點只保留「平均值」,而 Quantile Regression Forest 會保留該節點中所有樣本的實際輸出值 Y_i。
這裡可以看到一個重點是 QRF 依然是用 MSE 做爲分裂準則。
所以當我們要對新的樣本 x 做預測時, QRF 會將 x 丟進所有的樹中,每棵樹都會找到 x 所落入的葉節點, 並記錄該節點中所有樣本的索引。
這樣每個訓練樣本 i 就會得到一個權重 w_i(x),代表「在所有樹中,樣本 i 與 x 落在相同葉節點的頻率」。 這些權重構成了 x 在訓練樣本中的鄰近關係。
接著,QRF 會用這些加權樣本來估計條件分布,也就是利用加權樣本構建出一個 經驗累積分布函數 (Empirical CDF)。
有了這個分佈函數就可以預測任意想要的分位數。
這篇文章的內容就到這邊.